
| Assistive Robotics | Education and Robotics | Robot Learning | Human-Robot Trust |
Task-Learning Policies for Turn-Taking in Human-Robot Interaction
The objective of this research is to design task-learning policies (TLPs) for a robotic system that targets the exchange of task rules between humans and robots. This objective is achieved through a turn-taking application during a human-robot interaction where the two partners learn a task from each other and accomplish a shared goal. As a first step, a method to model human action primitives using a pattern-recognition technique is presented. Next, algorithms are developed to generate turn-taking strategies in response to human task behaviors. The main idea is to build a knowledge database that stores learned task cases, and to retrieve and adapt those experiences when similar tasks emerge. The contributions also include modeling TLP, deploying a physically embodied agent, and developing evaluation platforms.
Human Task Behavior Modeling:

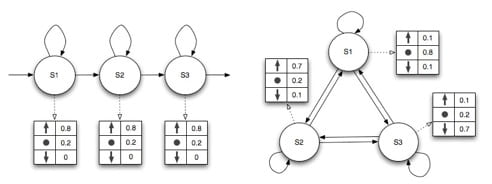
Case-based Turn-Taking Strategy:
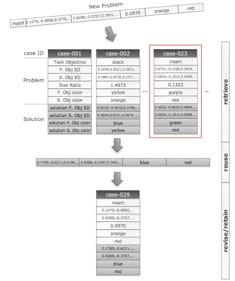
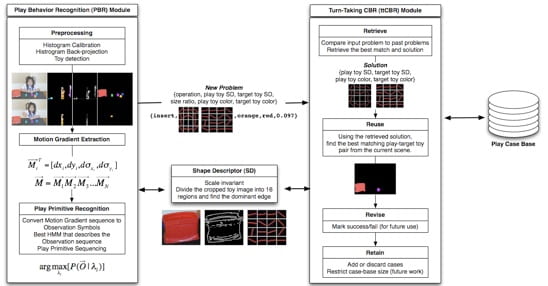
Learning from Teleoperation
Robots are rolling out of the research labs and walking, crawling and flying into our homes. As such the new description for a robot owner is changing. For example from the researcher or the science enthusiast, to the homemaker who needs a little help with the windows. To ease the challenge of programming robots for the new robot owner/operator learning from demonstration has been proposed. This form of features the operator demonstrating what they would like the robot do and the robot learning how to make it happen.
One of the challenges in the robotic learning portion of this process is that many robots do not yet have the ability to actively engage in the process. It is often the case that robots passively learn based on information provided to them. They are not equipped to perform meta-analysis about their experience, or at least to do so in a short enough time for it to be relevant in this learning process.
This research seeks to uncover quantitative metrics which can be generated by these robotic students. Such metrics can enable the robot to perform tasks like determining how much more training time it needs to master a task, assessing whether a particular set of instruction is likely to be helpful in the learning process, or even for determining if the provided instruction is coming from someone who knows what they are doing.
One Paradigm:
Omni + Pioneer:

